Lecture 10: Common Probability Distributions
When we output a forecast, we’re either explicitly or implicitly outputting a probability distribution.
For example, if we forecast the AQI in Berkeley tomorrow to be “around” 30, plus or minus 10, we implicitly mean some distribution that has most of its probability mass between 20 and 40. If we were forced to be explicit, we might say we have a normal distribution with mean 30 and standard deviation 10 in mind.
There are many different types of probability distributions, so it’s helpful to know what shapes distributions tend to have and what factors influence this.
From your math and probability classes, you’re probability used to the Gaussian or normal distribution as the “canonical” example of a probability distribution. However, in practice other distributions are much more common. While normal distributions do show up, it’s more common to see distributions such as log-normal or power law distributions.
In the remainder of these notes, I’ll discuss each of these in turn. The following table summarizes these distributions, what typically causes them to occur, and several examples of data that follow the distribution:
| Distribution | Gaussian | Log-normal | Power Law |
|---|---|---|---|
| Causes | Independent additive factors | Independent multiplicative factors | Rich get richer, scale invariance |
| Tails | Thin tails | Heavy tails | Heavier tails |
| Examples | -heights | -US GDP in 2030 | -city population |
| -temperature | -price of Tesla stock in 2030 | -twitter followers | |
| -measurement errors | -word frequencies |
Normal Distribution
The normal (or Gaussian) distribution is the familiar “bell-shaped” curve seen in many textbooks. Its probability density is given by $p(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\Big(-\frac{(x-\mu)^2}{2\sigma^2}\Big)$, where $\mu$ is the mean and $\sigma$ is the standard deviation.
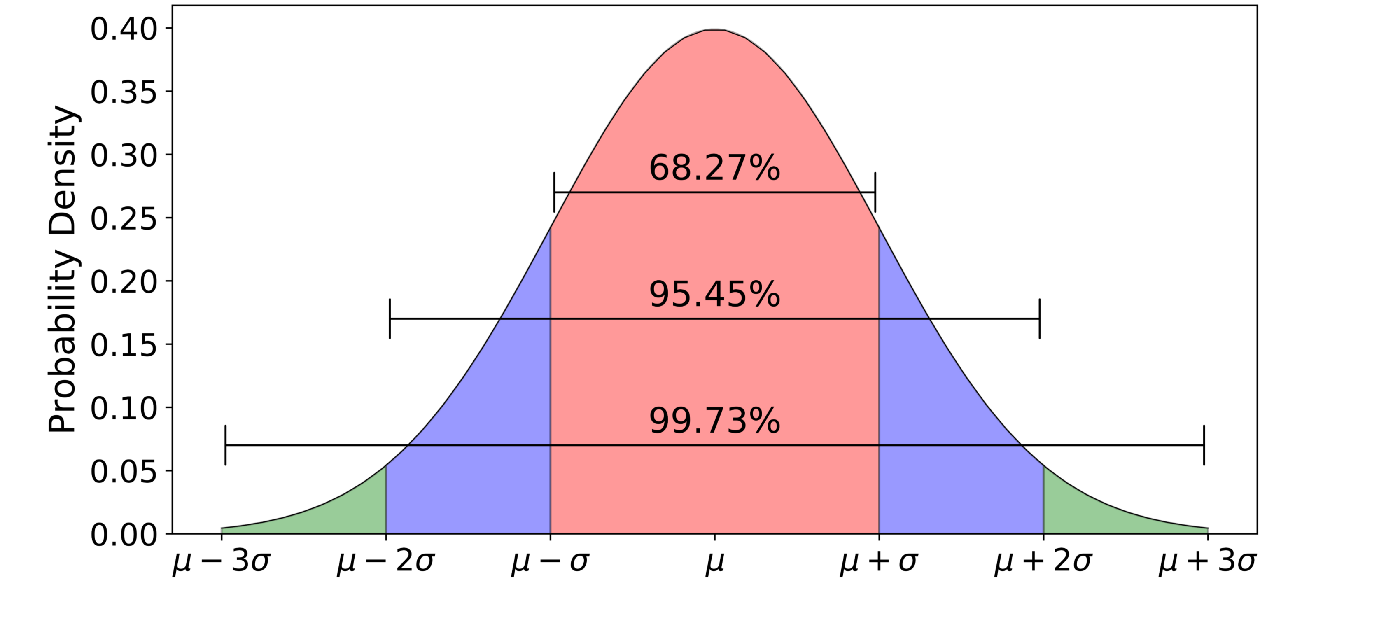
Normal distributions occurs when there are many independent factors that combine additively, and no single one of those factors “dominates” the sum. Mathematically, this intuition is formalized through the central limit theorem.
Example 1: temperature. As one example, the temperature in a given city (at a given time of year) is normally distributed, since many factors (wind, ocean currents, cloud cover, pollution) affect it, mostly independently.
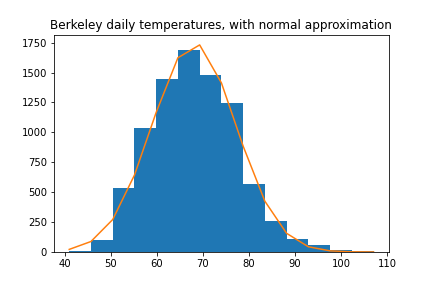
Example 2: heights. Similarly, height is normally distributed, since many different genes have some effect on height, as do other factors such as childhood nutrition.
However, for height we actually have to be careful, because there are two major factors that affect height significantly: age and sex. 12-year olds are (generally) shorter than 22-year-olds, and women are on average 5 inches (13cm) shorter than men. These overlaid histograms show heights of adults conditional on sex.
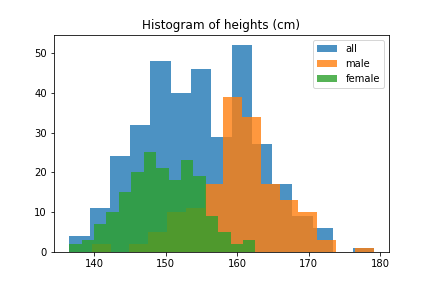
Thus, if we try to approximate the distribution of heights of all adults with a normal distribution, we will get a pretty bad approximation. However, the distribution of male heights and female heights are separately well-approximated by normal distributions.
| All | Males | Females |
|---|---|---|
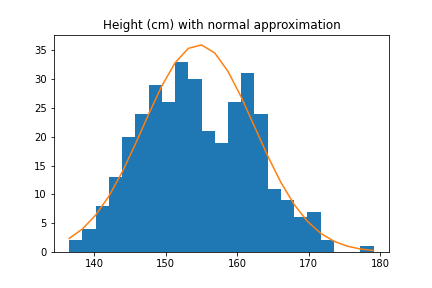 | 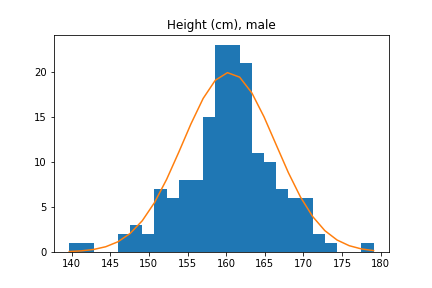 | 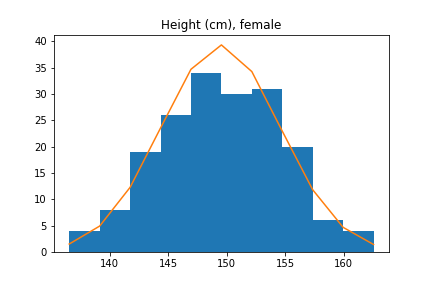 |
Example 3: measurement errors. Finally, the errors of a well-engineered system are often normally-distributed. One example would be a physical measurement apparatus (such as a voltmeter). Another would be the errors of a well-fit predictive model. For instance, when I was an undergraduate I fit a model to predict the pitch, yaw, roll, and other attributes of an autonomous airplane. The results are below, and all closely follow a normal distribution:

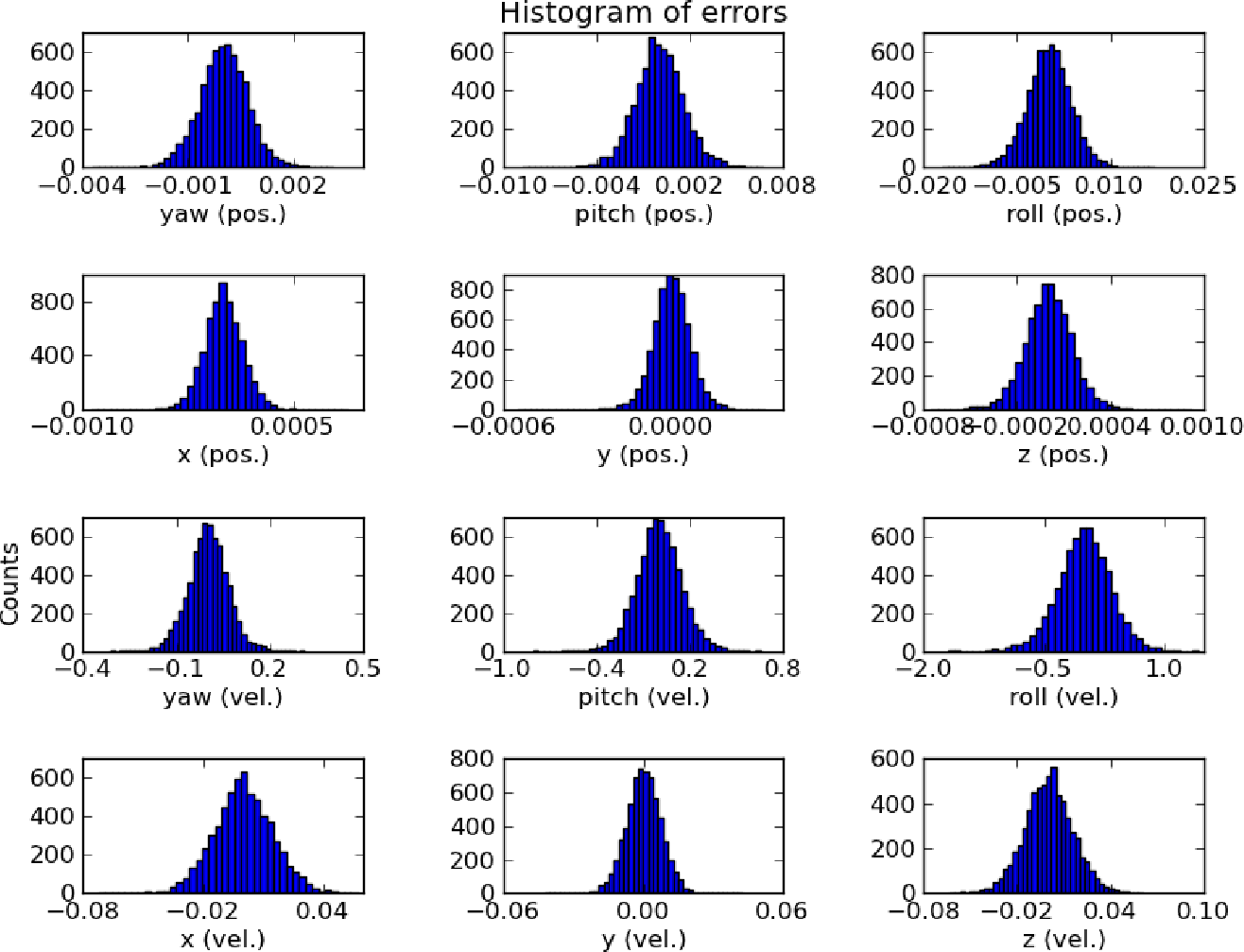
Why do well-engineered systems have normally-distributed errors? It’s a sort of reverse central limit theorem: if they didn’t, that would mean there was one large source of error that dominated the others, and a good engineer would have found and eliminated that source.
Brainstorming exercise. What are some other examples of random variables that you expect to be normally distributed?
Caveat: normal distributions have thin tails. The normal distribution has very “thin” tails (falling faster than an exponential), and once we reach the extremes the tails usually underestimate the probability of rare events. As a result, we have to be careful when using a normal distribution for some of the examples above, such as heights. A normal distribution predicts that no women should be taller than 6’8”, yet there are many women who have reached this height (read more here).
If we care specifically about the extremes, then instead of the normal distribution, a distribution with heavier tails (such as a t-distribution) may be a better fit.
Log-normal Distributions
While normal distributions arise from independent additive factors, log-normal distributions arise from independent multiplicative factors (which are often more common). A random variable $X$ is log-normally distributed if $\log(X)$ follows a normal distribution–in other words, a log-normal distribution is what you get if you take a normal random variable and exponentiate it. Its density is given by
$p(x) = \frac{1}{x\sqrt{2\pi\sigma^2}} \exp\Big(-\frac{(\log(x) - \mu)^2}{2\sigma^2}\Big)$.
Here $\mu$ and $\sigma$ are the mean and variance of $\log(X)$ (not $X$).
| Examples of log-normal distributions | Log-normal(0, 1) compared to Normal(0, 1) |
|---|---|
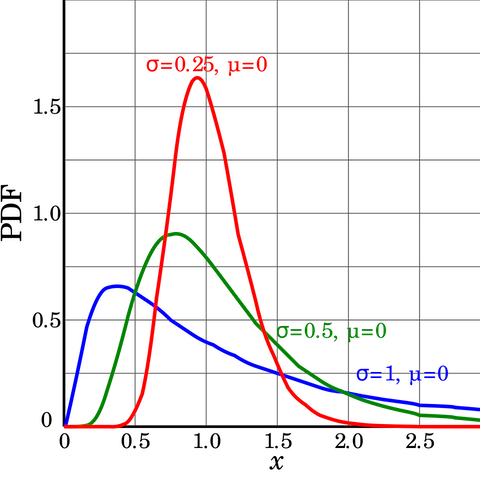 | 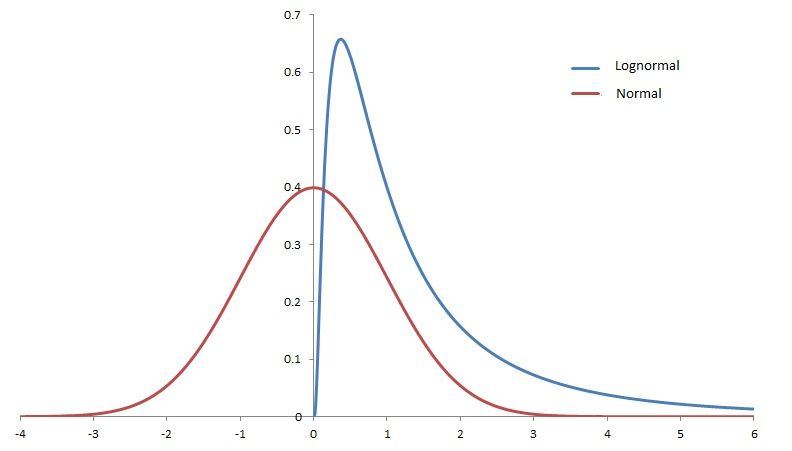 |
Multiplicative factors tend to occur whenever there is a “growth” process over time. For instance:
- The number of employees of a company 5 years from now (or its stock price)
- US GDP in 2030
Why should we think of factors affecting a company’s employee count as multiplicative? Well, if a 20-person company does poorly it might decide to lay off 1 employee. If a 10,000-person company does poorly, it would have to lay off hundreds of employees to achieve the same relative effect. So, it makes more sense to think of “shocks” to a growth process as multiplicative rather than additive.
Log-normal distributions are much more heavy-tailed than normal distributions. One way to get a sense of this is to compare heights to stock prices.
| Height (among US adult males) | Stock price (among S&P 500 companies) | |
|---|---|---|
| Median | 175.7 cm | $119.24 |
| 99th percentile | 191.9 cm | $1870.44 |
To check if a variable X is log-normal distributed, we can plot a histogram of log(X) (or equivalently, plot the x-axis on a log scale), and this should be normally distributed. For example, consider the following plots of the Lognormal(0, 0.9) distribution:
| Standard axes | Log scale x-axis |
|---|---|
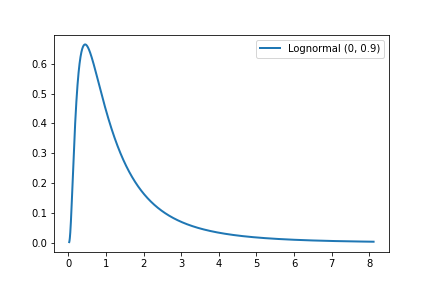 | 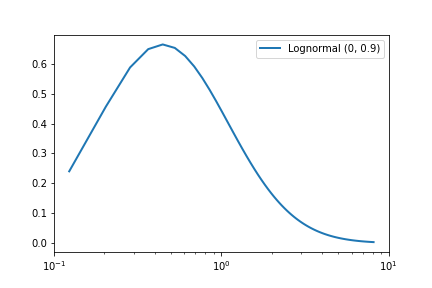 |
Brainstorming exercise. What are other quantities that are probably log-normally distributed?
Power Law Distributions
Another common distribution is the power law distribution. Power law distributions are those that decrease at a rate of $x$ raised to some power: $p(x) = C / x^{\alpha}$ for some constant $C$ and exponent $\alpha$. (We also have to restrict $x$ away from zero, e.g. by only considering $x > 1$ or some other threshold.)
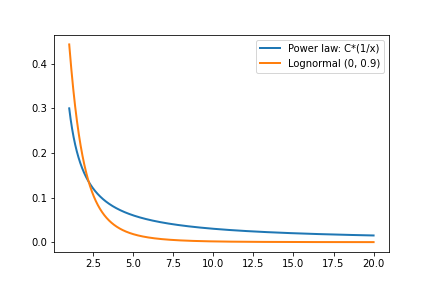
Like a log-normal distribution, power laws are heavy-tailed. In fact, they are even heavier-tailed than log-normals. To identify a power law, we can create a log-log plot (plotting both the x and y-axes on log scales). Variables that follow power laws will show a linear trend, while log-normal variables will have curvature. Here we plot the same distributions as above, but with log scale x and y axes:
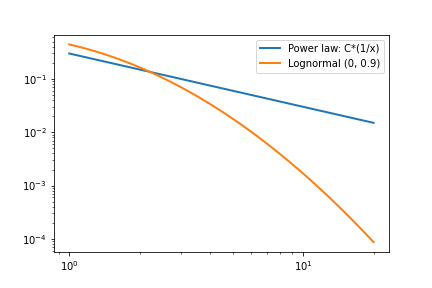
In practice, log-normal and power-law distributions often only differ far out in the tail and so it isn’t always easy (or important) to tell the difference between them.
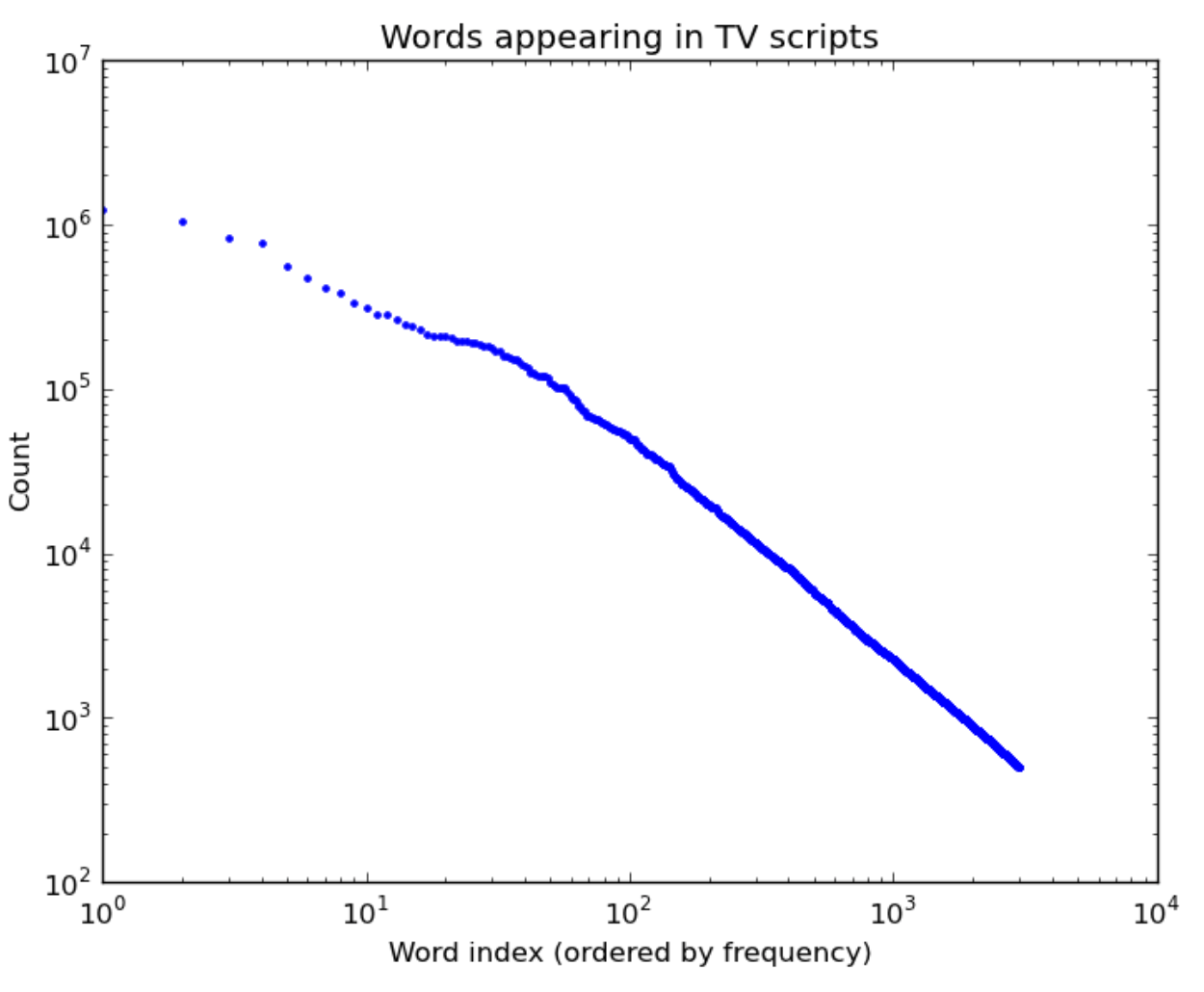
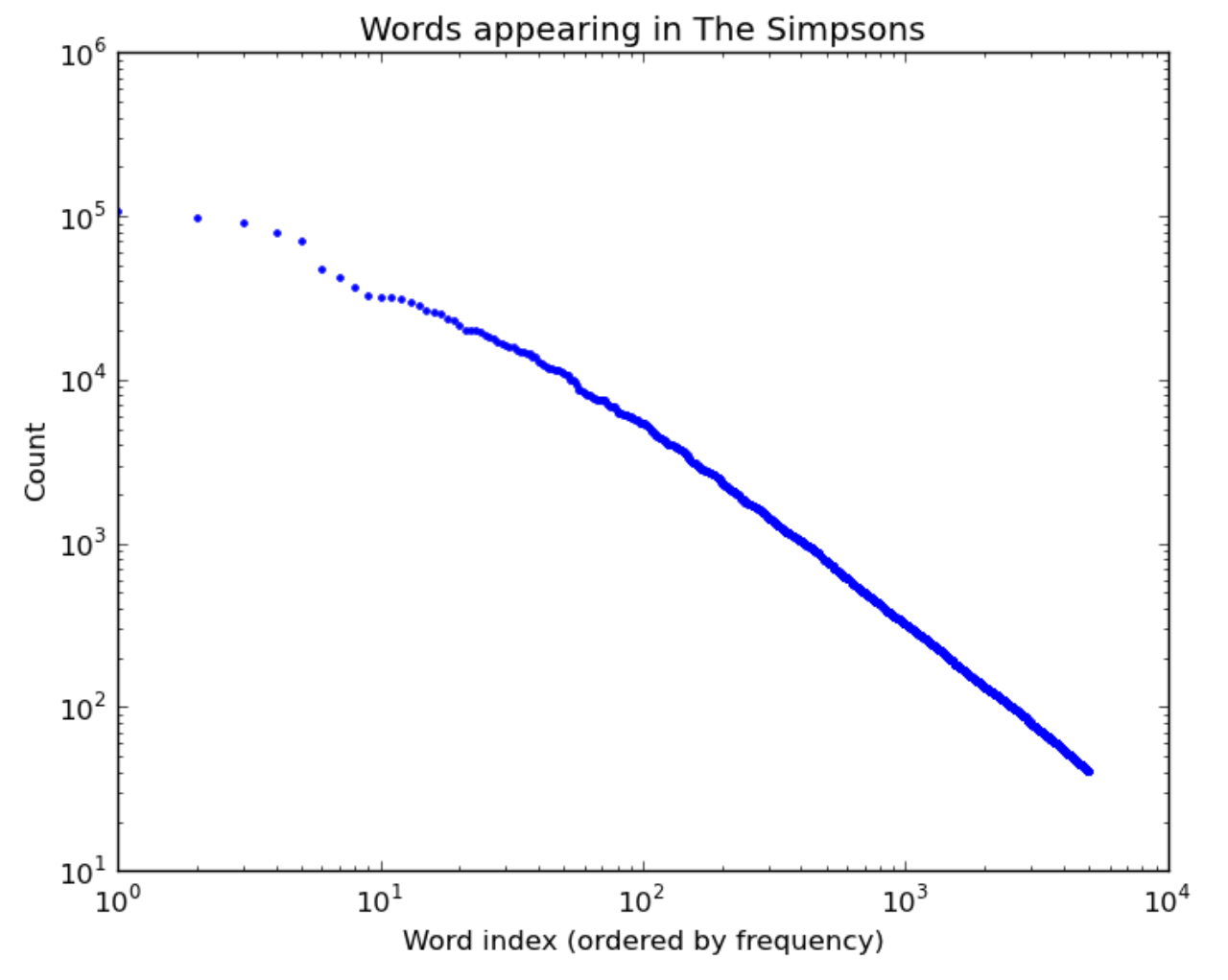
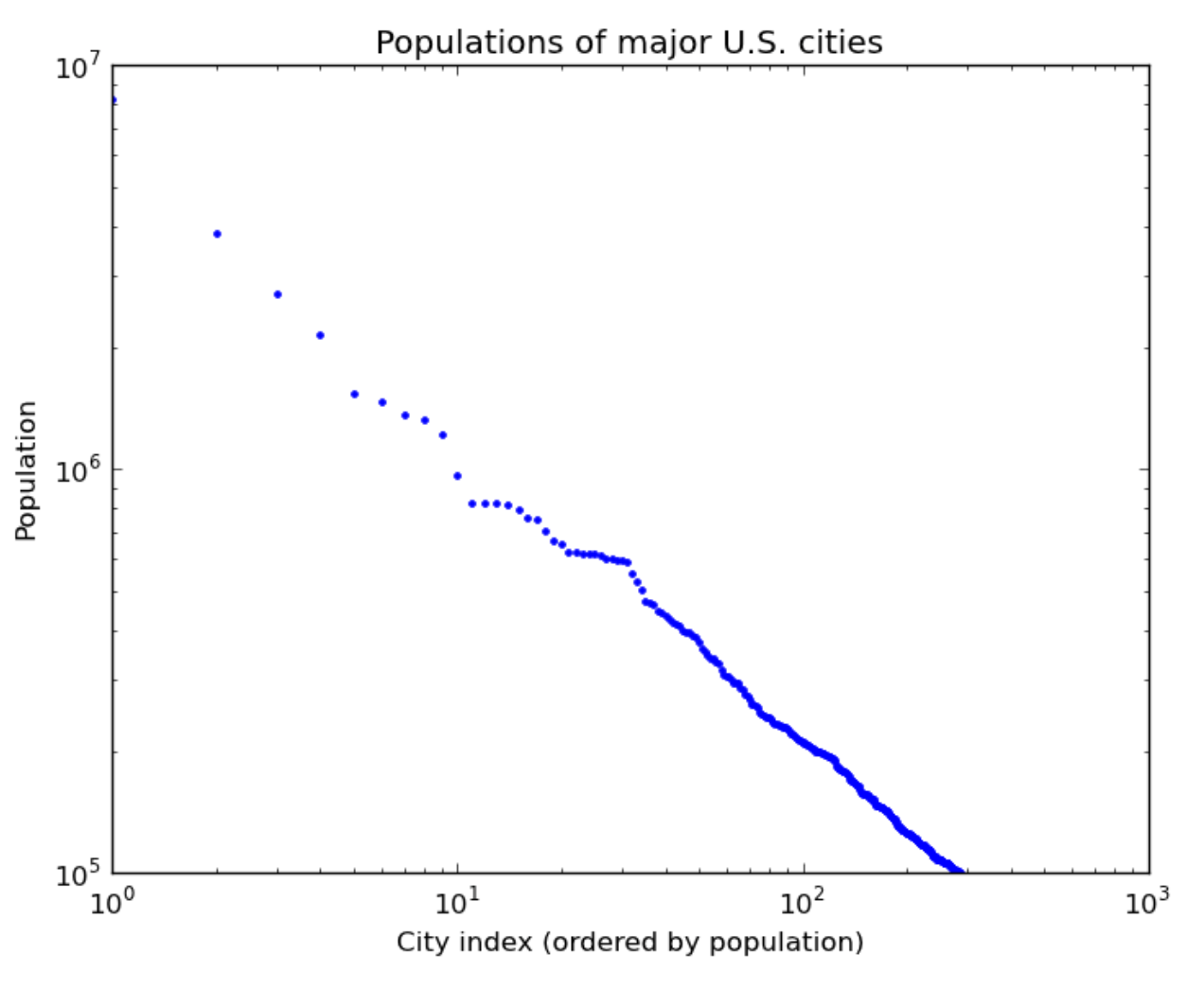
What leads to power law distributions? Here are a few real-world examples of power law distributions (plotted on a log-log scale as above):
| Words in TV scipts | Words in the Simpsons | US city populations |
|---|---|---|
 |  |  |
The factors that lead to power law distributions are more varied than log-normals. For a good overview, I recommend this excellent paper by Michael Mitzenmacher. I will summarize two common factors below:
One reason for power laws is that they are the unique set of scale-invariant laws: ones where $X$ and $2X$ (and $3X$) all have identical distributions. So, we should expect power laws in any case where the “units don’t matter”. Examples include the net worth of individuals (dollars are an arbitrary unit) and the size of stars (meters are an arbitrary unit, and more fundamental physical units such as the Planck length don’t generally affect stars).
Another common reason for power laws is preferential attachment or rich get richer phenomena. An example of this would be twitter followers: once you have a lot of twitter followers, they are more likely to retweet your posts, leading to even more twitter followers. And indeed, the distribution of twitter followers is power law distributed:
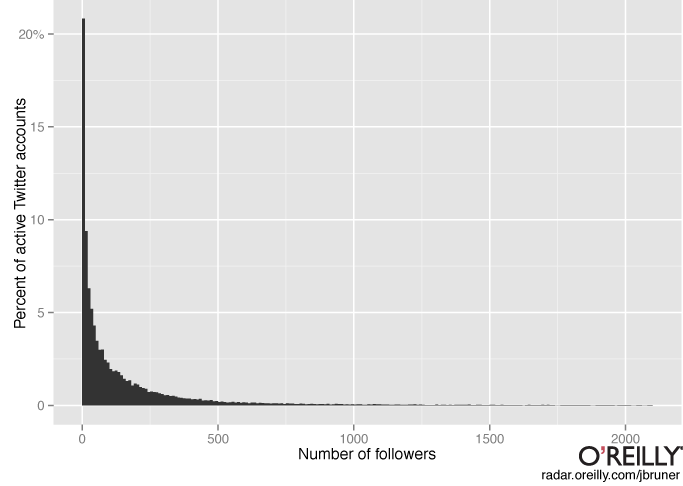
“Rich get richer” also explains why words are power law distributed: the more frequent a word is, the more salient it is in most people’s minds, and hence the more it gets used in the future. And for cities, more people think of moving to Chicago (3rd largest city) than to Arlington, Texas (50th largest city) partly because Chicago is bigger.
Brainstorming exercise. What are other instances where we should expect to see power laws, due to either scale invariance or rich get richer?
Exercise. Interestingly, in contrast to cities, country populations do not seem to fit a power law (although they could fit a mixture of two power laws reasonably):
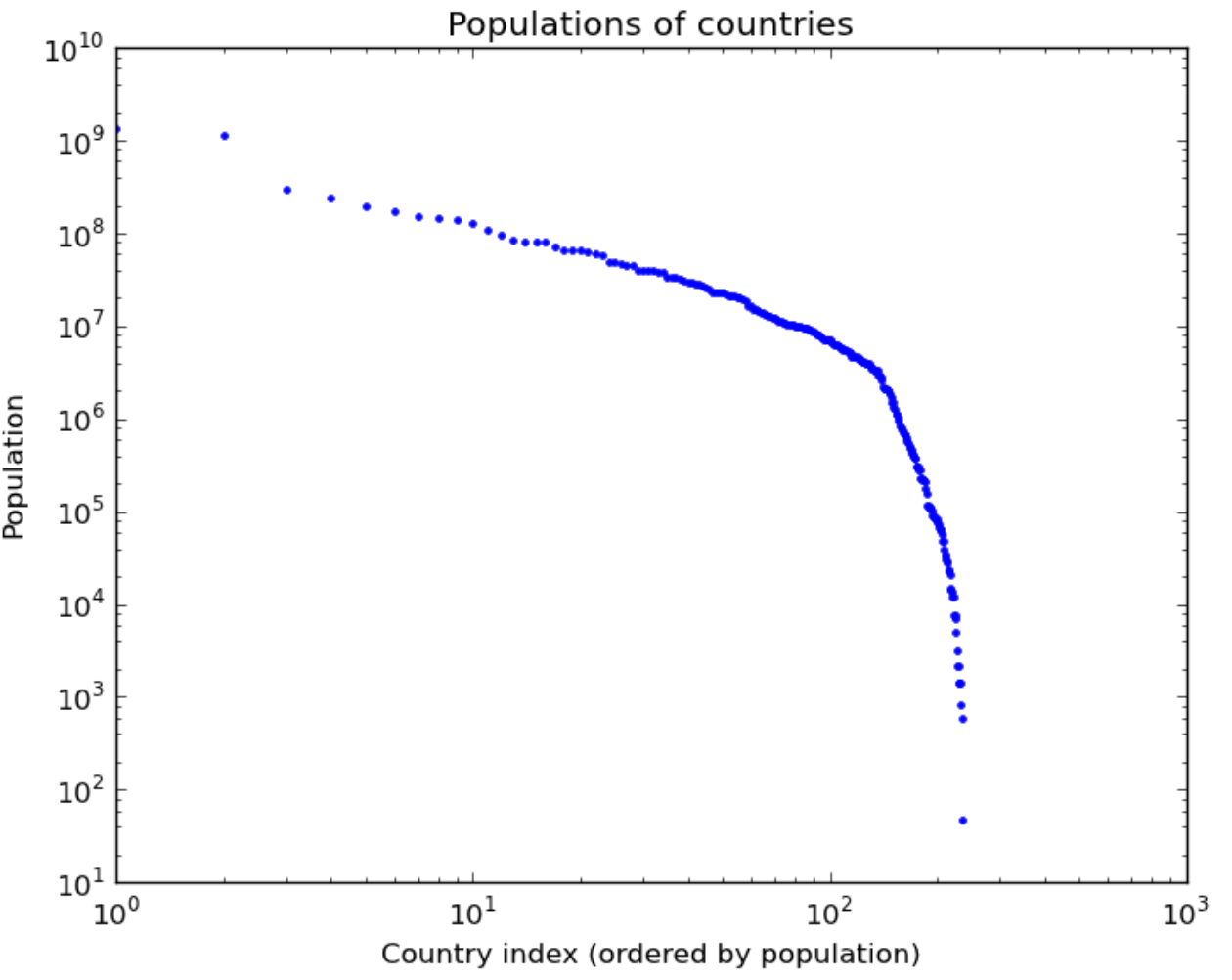
Can you think of reasons that explain this?
There is much more to be said about power laws. In addition to the Mitzenmacher paper mentioned above, I recommend this blog post by Terry Tao.
Concluding Exercise. Here are a couple examples of data you might want to model. For each, would you expect its distribution to be normal, log-normal, or power law?
- Incomes of US adults
- Citations of papers
- Number of Christmas trees sold each year